The part of the software that specifically solves problems from the domain model usually
constitutes only a small portion of the entire software system, although its
importance is disproportionate to its size. To apply our best thinking, we need to be able
to look at the elements of the model and see them as a system.We must not be forced to
pick them out of a much larger mix of objects, like trying to identify constellations in the
night sky.We need to decouple the domain objects from other functions of the system, so
we can avoid confusing domain concepts with concepts related only to software technology
or losing sight of the domain altogether in the mass of the system.
Domain-Driven Design: Tackling Complexity in the Heart of Software, by Eric Evans
(Addison-Wesley, 2004)
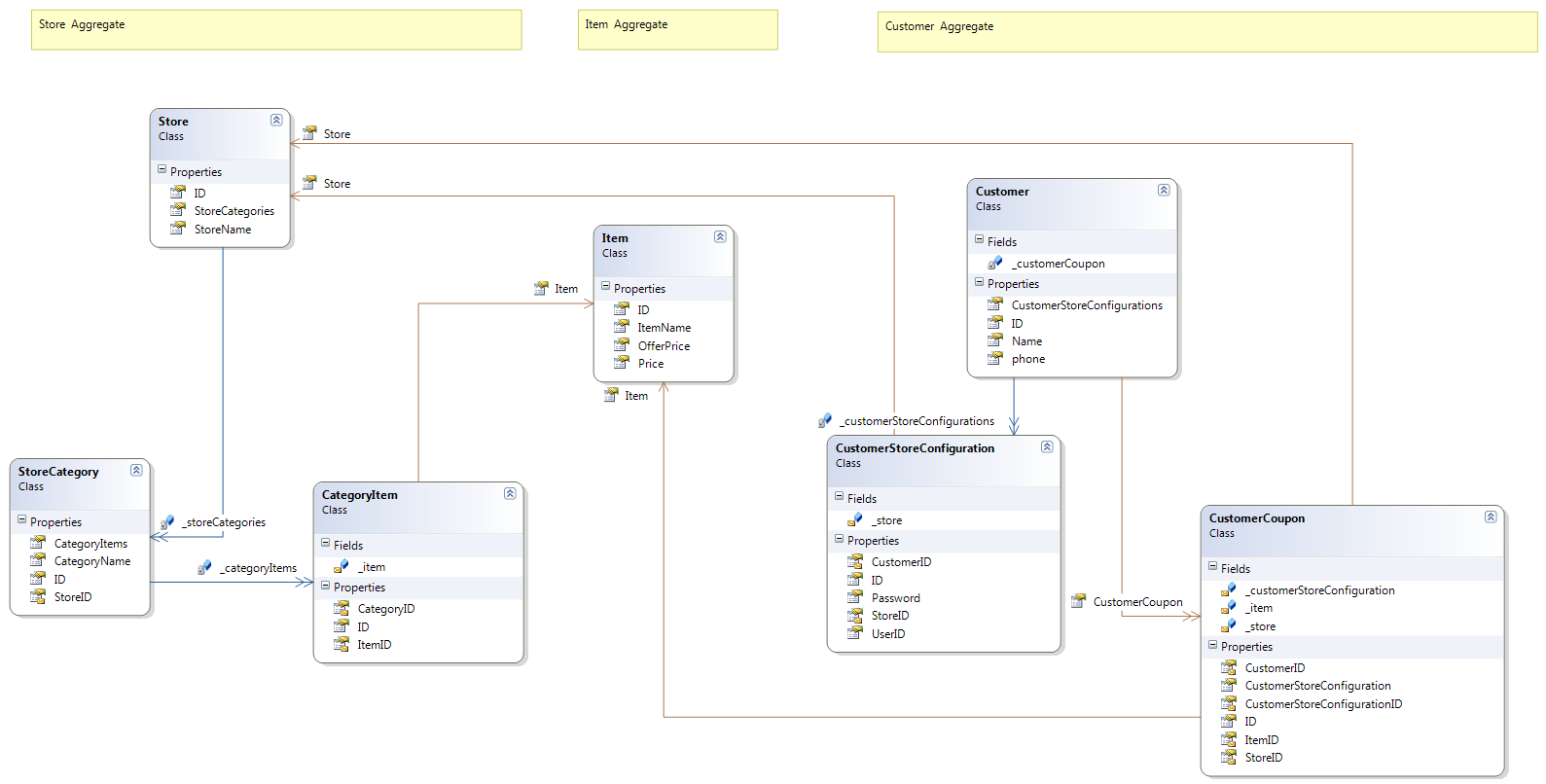
Aggregates and Simplification
The DDD way to break down this complexity is to arrange domain entities into groups
called aggregates.
called aggregates.
Each aggregate has a root entity that defines the identity of the whole aggregate, and acts
as the “boss” of the aggregate for the purposes of validation and persistence. The aggregate is
a single unit when it comes to data changes, so choose aggregates that relate logically to real
business processes—that is, the sets of objects that tend to change as a group (thereby embedding
further insight into your domain model).
Objects outside a particular aggregate may only hold persistent references to the root
entity, not to any other object inside that aggregate (in fact, ID values for non-root entities
don’t even have to be unique outside the scope of their aggregate). This rule reinforces
aggregates as atomic units, and ensures that changes inside an aggregate don’t cause data
corruption elsewhere.
as the “boss” of the aggregate for the purposes of validation and persistence. The aggregate is
a single unit when it comes to data changes, so choose aggregates that relate logically to real
business processes—that is, the sets of objects that tend to change as a group (thereby embedding
further insight into your domain model).
Objects outside a particular aggregate may only hold persistent references to the root
entity, not to any other object inside that aggregate (in fact, ID values for non-root entities
don’t even have to be unique outside the scope of their aggregate). This rule reinforces
aggregates as atomic units, and ensures that changes inside an aggregate don’t cause data
corruption elsewhere.
In our example we have 3 aggregates (Customer,Store and Item)
No comments:
Post a Comment